Azure Cosmos DB APIs 4th Aug 2021

In this blog, we will explore Azure Cosmos DB as a part of the non-relational database system and also understand the differences between various APIs available in Azure Cosmos DB. The idea of the blog is to help you make an informed decision on which Azure Cosmos DB API to choose when ever you plan to migrate your on-premise database to the cloud. I have tried to put as much information as I can about each Database API.Hope you would like it
These days, non-relational database systems are used widely across
variety of applications.
1).
A globally distributed and elastically scalable database. With
single-digit millisecond reads and writes worldwide, and with the
capability to elastically scale from thousands to hundreds of
millions of requests per second, Cosmos DB offers
unparalleled throughput .
2).
It also offers low latency. To achieve low latency you can deploy instances of the applications in multiple data centers. In modern web-based applications, low latency is expected by the end-users. With Cosmos DB you can store data closer to application users. The database can be distributed and available in 50+ regions. You can choose the regions which are closer to your customer, based on your scenarios
3).
As mentioned above, you can develop solutions that guarantee low latency that is backed by comprehensive SLAs.You can also ensure High Availability for business continuity. Cosmos DB replicates the data to all Azure regions associated with the cosmos account while maintaining the application's high availability. Region management can be involved at any time in the application lifecycle.
4).
Fully managed platform-as-a-service (PaaS) - Being serverless and since it automatically scales based on your application's traffic, it is cost-effective
5).
It is schema-agnostic, horizontally scalable, and a NoSQL Database. Schema-agnostic means that no schema is enforced when adding items. With relational databases, schemas are required to be defined at design time. This becomes restrictive as the application grows.
6).
Enables you with the ability to use document,wide-column,graph-based, or key-value data.
7).
Based on the Javascript programming model and Core(SQL) API is embedded into the Javascript type system, expression evaluation, and function invocation.
Distributed applications make a fair trade-off between data
consistency, availability, and latency. While maintaining data
over multiple regions, the foremost and most frequent challenge is
the latency as when the data is made available to the other
databases. For example, when data is written to the database in
Australia, users from Australia will be able to see that data
sooner than compared to users from saying the US. If you are
wondering why the reason is obvious, i.e it is due to the latency
in synchronization between the two regions. As a solution, there
are a few modes that customers can choose from as Cosmos DB’s
multi-master replication model offers five consistency models. You
can configure them according to your needs and define how often or
how soon they want their data to be made available in the other
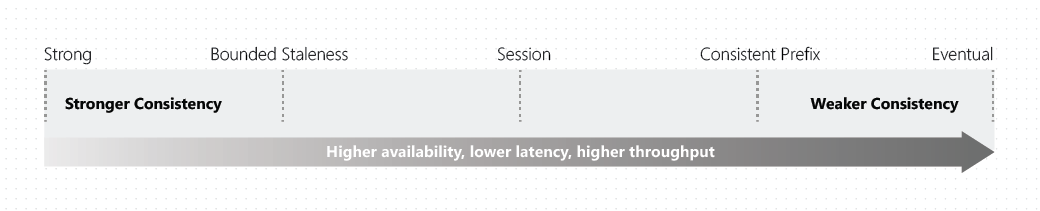
regions. five levels of consistency are as follows.
- Strong
- Bound staleness
- Session
- Consistent prefix
- Eventual
 Source
Source
In most NoSQL databases, there are only two levels – Strong and Eventual. Eventual being the least consistent while Strong on the other end being the most consistent level. However, as we move from Strong to Eventual, consistency decreases but availability and throughput increases.You can refer Microsoft official documentation link above for more details
Azure Cosmos Databases,Containers,& Items
Now let's see what are different elements in an Azure Cosmos account.First of all, in order to start using Azure Cosmos DB, you should initially create an Azure Cosmos account in your Azure resource group in the required subscription.Once you have that, then you can create databases containers and items under it
An Azure cosmos container is the fundamental unit of scalability for provisioned throughput and storage. You can virtually have an unlimited provisioned throughput (RU/s) and storage on a container. It can be scaled elastically, horizontally partitioned, and then replicated across multiple Azure regions. You can specify a logical partition key and based on that Azure Cosmos DB transparently partitions your container in order to elastically scale your provisioned throughput and storage
Cosmos DB stores "items" in "containers".These 2 concepts are represented differently based on which API you are using.It would be "documents" in "collections" when using MongoDB-compatible API.Same way, it would be node or edge when using Gremlin API.A quick table for your reference below
| Cosmos Entity/API | Cosmos Item |
|---|---|
| SQL Core API | Item |
| MongoDB API | Document |
| Gremlin/Graph base API | Node or Edge |
| Table API | Item |
| Cassandra API | Row |
Picking the right Azure Cosmos DB API
There are five different APIs available in Azure Cosmos DB. With so many API options comes the complexity of which API to choose. Each API option has its own pros and cons but it all depends on your particular use case, requirements, your team strengths, etc- so which one to pick?
1).
Core (SQL) API Provides the flexibility of a NoSQL document store combined with the power of SQL for querying.
2).
MongoDB API: Supports the MongoDB wire protocol so that existing MongoDB clients continue to work with Azure Cosmos DB as if they are running against an actual MongoDB database
3).
Cassandra API: Supports the Cassandra wire protocol so that existing Apache drivers compliant with CQLv4 continue to work with Azure Cosmos DB as if they are running against an actual Cassandra database.
4).
Gremlin API: Supports graph data with Apache TinkerPop (a graph computing framework) and the Gremlin query language.
5).
Table API: Provides premium capabilities for applications written for Azure Table storage.
Now above we saw the available API options but let's see which one to select based on the scenario. Based on my personal experience, there is no perfect formula. In few cases, the choice will be clear but most scenarios demand some analysis before picking the API. Based on my personal experience, these are few steps to consider which may help you zero in on the right API.
a).
The first and the obvious point to consider is if you have an
existing MongoDB, Cassandra, or Gremlin application.If the answer
is yes, then it's pretty obvious which API to pick. Just consider
using the specific Azure Cosmos DB API (for eg Mongo DB API if
your existing application is on MongoDB etc).
Doing so :
- Will reduce your migration tasks,
- You need not rewrite the entire data access layer and
- Most important point is, you can leverage your team's experience as there is no need to train them on the new technology
b).
If your project requires you to support semi-structured data, then that means your schema has to be flexible. Therefore, in cases where you expect the schema to change a lot, you should probably go with a document database, making Core (SQL) a good choice (although MongoDB API can also be considered). Now to help you narrow down further, consider this:
- If you are developing your project completely from scratch, then go ahead with Core (SQL).
- Also, for instance, say you are planning to migrate from an existing traditional relational database, then also Core (SQL) should be the way to go ahead. Even though core (SQL) won't allow you for any code reuse, your team should quickly get up-to-speed with the SQL-like query language that is supported by Core (SQL).
- Like mentioned in the point above,(point a) consider MongoDB API if your existing application was in MongoDB
c).
If your data model consists of relationships between entities with associated metadata then you should consider Azure Cosmos DB Gremlin API. If you don't get it, don't worry, let me try to put it in simpler words. Use it when you see there is important "data" about the relationships "between items" in the database i.e applications where relationships in data also contribute to meaning and value. A graph database enables you to discover connections among data.
GremlinAPI allows users to make graph queries and stores data as edges and vertices. Use this API for use cases where dynamic data is involved or data has complex relations. Consider a scenario where you host an eCommerce website and you want to give the best-personalized customer experience to your clients. If you ask me how, maybe, by providing recommendations for products on your website. In order to achieve this, your solution would need to predict customer behavior. For eg, if your customer bought a dash camera on your website, then your solution can also suggest buying a memory card for it. So what it means is that if a customer has bought product A, analyze the data and recommend your customer to buy product B too, because that's what the customer may want based on his previous interactions or may be based on other customers which bought similar dash camera and share same interests as your customer. So you can see that this has become a bit complicated and that is when you know you need graph/Gremlin API.
Other scenarios where Gremlin API may be useful in managing connected social networks, Geospatial use cases such as finding a location of interest within an area or locate the shortest/optimal route between two locations, or modeling network and connections between IoT devices as a graph in order to build a better understanding of the state of your devices and assets. Basically, these are systems where the data topology is difficult to predict. Like mentioned earlier, a graph database empowers you, as you can uncover connections among data, and do so much faster than any other NoSQL database such as MongoDB or Core(SQL) let alone joining tables within a traditional relational database.Please refer to Microsoft official documentation link for more detail . Link here
d).
If your application needs to handle a high volume, real-time data, Apache Cassandra is an ideal choice. This API stores data in the column-oriented schema. Like we saw with other APIs if your existing application is built on Cassandra, then without any doubt choose Cassandra API. This API also offers a highly distributed, horizontally scaling approach to storing large volumes of data while offering a flexible approach to a column-oriented schema.
Cassandra API shares similar design qualities to Google’s Big Table and to an extent Amazon’s DynamoDB in that it uses a key-value system in which the keys point to column families that represent the structure of the stored data. Having said that, personally, I would say that querying in Cassandra is different and easier compared to DynamoDB and BigTable. Cassandra uses CQL (Cassandra Query Language) as a query language, which is very much similar to SQL. Since CQL is similar to SQL, the learning curve is far lesser if your developers are familiar with SQL.
Cassandra can handle high read/write throughputs; this makes it an excellent option for workloads such as messaging apps, event logging, IoT and metrics data collection, etc. As we know by now, Cosmos DB guarantees the consistency of throughputs, and therefore, it goes very well with Cassandra API as Cassandra has the ability to handle high throughputs.
Another scenario for Cassandra is when there is a need for high availability and low tolerance of outages. Again, Cassandra’s distributed design makes it almost certain that there is no single point of failure and when paired with Cosmos DB’s guarantee of service availability.Business-critical, all-important workloads can be reliably deployed and hosted on Azure.
By now, you might have got a fair bit idea on when to choose Cassandra API. Let's dig deeper and compare it with Mongo DB API. Few points are below:
- Cassandra uses columns and tables to store data, while MongoDB stores data in JSON-like documents. As mentioned above Cassandra has its own Query language called CQL. Its syntax is similar to SQL with some limitations. On the other hand, MongoDB uses queries structured into JSON fragments and doesn't have query language support yet. Though queries are easy and one can learn them quickly, if you are familiar with SQL then there will be some learning curve and maybe a change of mindset to query structured into JSON fragments
- MongoDB’s data model is categorized as object and document-oriented. It does not require a schema, naturally making it more adaptable to changes. Therefore, if you need a rich data model, MongoDB may be the better solution. Its unstructured architecture gives you more flexibility as you can depict any kind of object structure which can have properties(even nested for multiple levels). Such flexibility means the database can input documents of different structures and interpret them easily in the application. On the other hand, Cassandra is much more of a stationary database and is a more traditional model. It facilitates static typing and demands the categorization and definition of columns beforehand. It has a table structure using rows and columns. Having said that, it is still far more flexible than traditional relational databases since each row is not required to have the same columns. When created, these columns are dynamically assigned one the available Cassandra built-in data types. So Cassandra should be sufficient if you are NOT expecting too much deviation in the data structure
- Consider MongoDB API if your application has small or medium-sized traffic. Consider Cassandra when your application has high volume, real-time data.
- When it comes to data availability, and if your application is mission-critical demanding extremely high availability, then stick with Cassandra. MongoDB has a single master node that directs multiple slave nodes. If for some reason master goes offline, one of the slave nodes would replace it and take over the responsibility of the master node. Although this failover strategy ensures recovery, it may take some time for slaves to become masters. On the other hand, like mentioned earlier, Cassandra’s distributed design makes it almost certain that there is no single point of failure and when paired with Cosmos DB’s guarantee of service availability, business-critical, all-important workloads can be reliably deployed and hosted on Azure.
- If scalability and writing speed is important for your application, then go ahead with Cassandra. The reason is obvious. Cassandra allows for multiple master nodes, which greatly enhances its write-scalability. You can specify the number of nodes you want in a cluster. The more the number of nodes, the more scalable your database is and allows this database to coordinate numerous writes at the same time, all coming from its masters. On the other hand, MongoDB follows a master-slave architecture. It only allows a single master node. while the rest of the nodes in a cluster are slaves. When data is being written to the master node, you can only carry our read operations on the slave nodes. Therefore, MongoDB is not as scalable as Cassandra. However, one can improve the scalability of MongoDB via Sharding, distributing data across several machines and promoting high throughput operations with large sets of data. Those might require some setting up, though.
Quick trade-off of NoSQL Database
Can't replace RDBMS and ACID. If you need to store data using rows and columns, in a structured format, stick to one of the many available relational databases. Additionally, if you need ACID-compliant databases, NoSQL is probably not the best solution. For database transactions that ensure atomicity, consistency, isolation, and durability, it is better to use relational databases, such as SQLServer or MYSQL
Conclusion.
To conclude, I hope you got a better idea of Azure Cosmos DB. I
also hope you would be in a better position to decide which API to
choose if you are considering moving from on-premises to the
cloud. As mentioned above, I have tried to put and provide as many
details as I can about each API. From personal experience, I would
say that take some time on analysis before migrating data from
traditional DBs to Cosmos in order to avoid hassles later..
And that's it. Hope this article was helpful. .Email me at "techspacedeck@gmail.com" incase you have queries. Alternatively, you can fill the "CONTACT" form or drop a comment below
